
Competitor Backlink Analysis using Python involves using Python programming language and various libraries like requests, BeautifulSoup, pandas, and matplotlib to gather and analyze the backlinks of your competitors’ websites. Backlinks are hyperlinks from other websites that point to a particular website, and they play a crucial role in search engine ranking and website authority.
The process begins by providing a list of competitor URLs. The Python script then sends HTTP requests to each competitor’s website, retrieves the HTML content, and uses BeautifulSoup to parse the data and extract relevant information, specifically the backlinks.
Once the backlinks are obtained, the data is organized into a DataFrame using pandas, which allows for easy data manipulation and analysis. The script calculates the number of backlinks for each competitor, sorts the results in descending order, and presents the findings in a tabular format.
Additionally, the script employs matplotlib to create a bar chart visualization, showing the number of backlinks for each competitor. This graphical representation aids in better understanding the backlink distribution among competitors.
Competitor backlink analysis is an essential part of search engine optimization (SEO) strategies, as it helps identify potential link-building opportunities, analyze the strength of competing websites, and benchmark your website’s backlink profile against your competitors. By understanding your competitors’ backlink strategies, you can make informed decisions to improve your own website’s ranking and authority in search engines.
Using this Python tool we can filter the competitor backlink, as there may be some 404 or 500 error backlinks.
Step 1:
Create a folder on desktop –

Download a referring domain list of your desired competitor from Seranking –

Now open the excel file and edit it as follows –

Remove all column except these two.

Filter DT to high to low. And remove all link from 40 DT, we only required high DT 100 to 40.
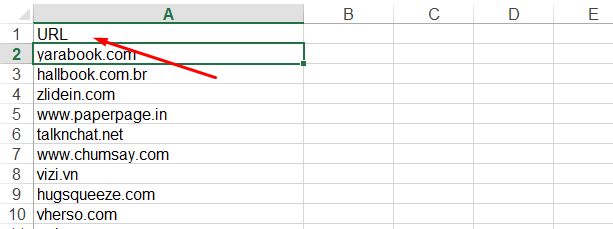
Now remove the DT column and rename the heading to “URL”
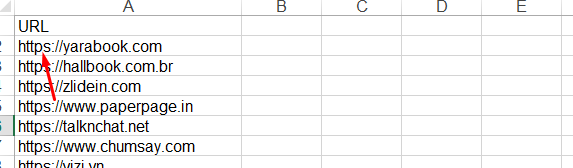
Make sure to add https:// before all URLs.

Save the file on that folder, rename it to “url”
Step 2:
Open anaconda prompt –
Using cd code open the folder.
Run 2 pip code –
pip install requests
pip install pandas
Step 3:
import requests
import pandas as pd
def check_url(url):
try:
response = requests.head(url)
return response.status_code
except requests.exceptions.RequestException:
return “Unreachable”
# Load Excel sheet into a DataFrame
excel_file = ‘C:/Users/SUMAN/Desktop/Keyword/url.xls’
df = pd.read_excel(excel_file)
# Create new columns to store the status information
df[‘Status’] = ”
df[‘Status Category’] = ”
# Iterate over each URL in the DataFrame
for index, row in df.iterrows():
url = row[‘URL’]
status_code = check_url(url)
if status_code == “Unreachable”:
df.at[index, ‘Status’] = “Unreachable”
df.at[index, ‘Status Category’] = “Unreachable”
elif status_code >= 500:
df.at[index, ‘Status’] = status_code
df.at[index, ‘Status Category’] = “Server Error”
elif status_code == 404:
df.at[index, ‘Status’] = status_code
df.at[index, ‘Status Category’] = “404 Not Found”
# Filter URLs based on status category
unreachable_urls = df[df[‘Status Category’] == “Unreachable”]
server_error_urls = df[df[‘Status Category’] == “Server Error”]
not_found_urls = df[df[‘Status Category’] == “404 Not Found”]
good_urls = df[(df[‘Status Category’] != “Unreachable”) & (df[‘Status Category’] != “Server Error”) & (df[‘Status Category’] != “404 Not Found”)]
# Export filtered URLs to a new Excel file
output_file = ‘C:/Users/SUMAN/Desktop/Keyword/file.xlsx’
with pd.ExcelWriter(output_file) as writer:
unreachable_urls.to_excel(writer, sheet_name=’Unreachable URLs’, index=False)
server_error_urls.to_excel(writer, sheet_name=’Server Error URLs’, index=False)
not_found_urls.to_excel(writer, sheet_name=’404 Not Found URLs’, index=False)
good_urls.to_excel(writer, sheet_name=’Good URLs’, index=False)
print(f”Filtered URLs exported to ‘{output_file}’.”)
Edit the code –
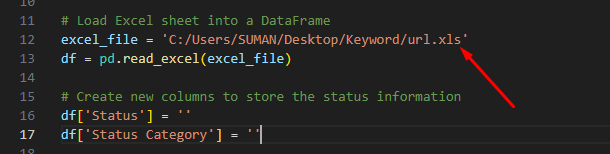
Replace the folder path.
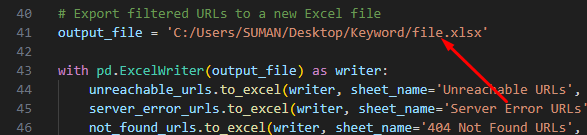
Replace the output folder path.

Save the code as python, and rename it as backlink.py
Python backlink.py
Run the code on anaconda prompt –
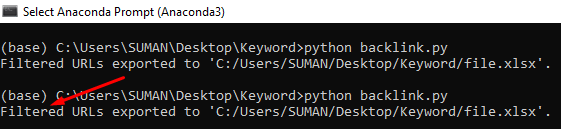
Now an excel file exported on that folder.

Open the file –

As we can see 4 types of URL list found.
Ignore all, only good URLs required.
Now we have a good working list of competitor backlinks.